背景
- 最近涉及到一个docker gpu使用场景,gpu服务器存在11.7、12.1两个cuda版本,程序A已经跑在cuda11.7上,我需要启动程序B,而程序B需要依赖cuda12.1。
问题
- 那么如何在不影响现有程序A的情况下,运行程序B,让服务器同时运行两套或者多套cuda呢?
分析
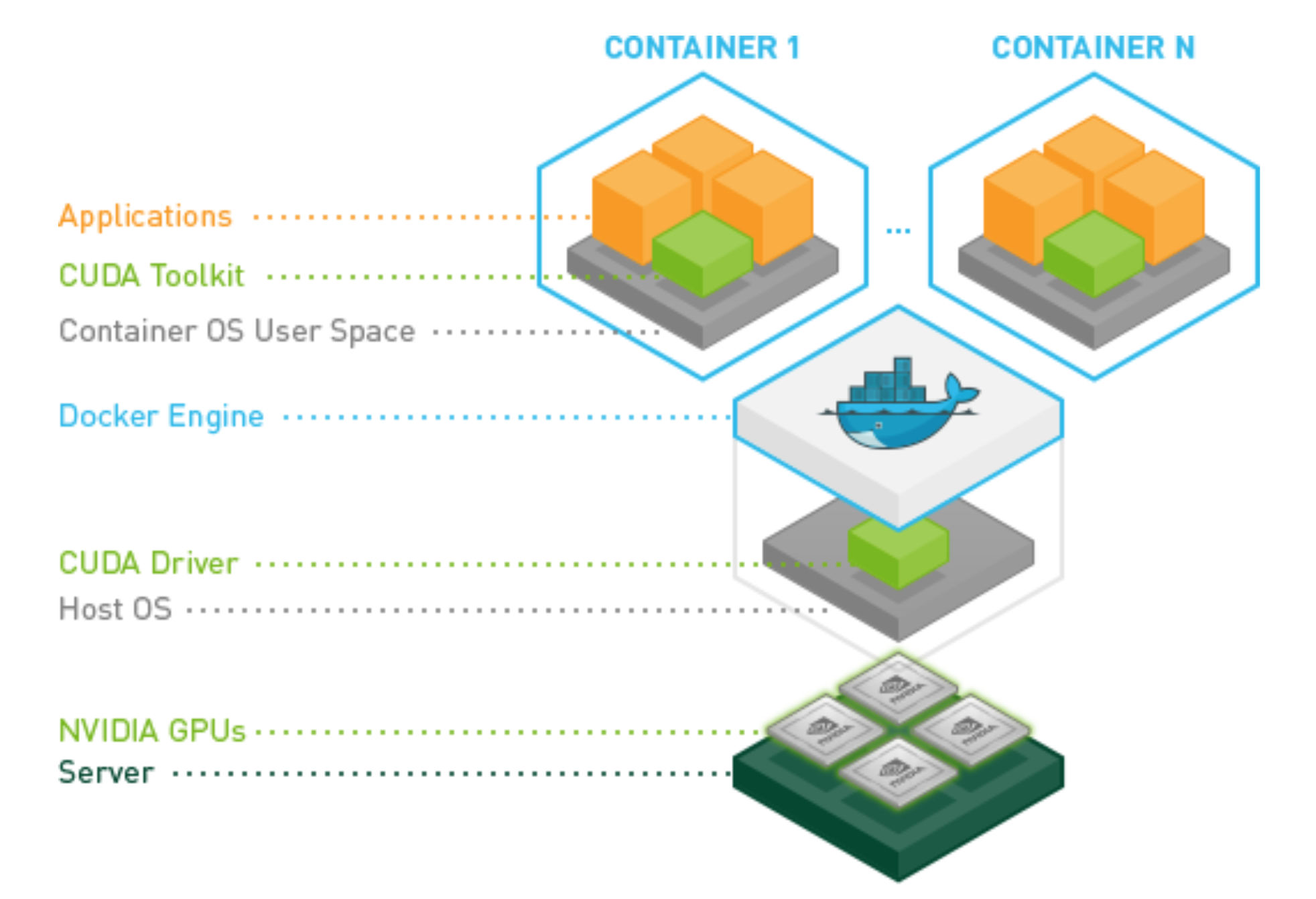
- 一般将调用gpu的程序打包到docker中时,会优先使用nvidia/cuda官方镜像,使得可以在docker容器内调用宿主机的gpu,官方镜像在启动docker容器时,会自动将当前linux用户下的环境变量传入docker
- 运行程序A和程序B的用户,需要为不同用户,比如:user01、user02
- linux不同用户的环境变量env是隔离的,可以通过修改环境变量的方式,使当前用户涉及到cuda的环境变量指向所需的cuda版本,然后传入docker,即可启动
方案
1. host 修改环境变量: `vi ~/.bashrc`
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
2. host 生效环境变量
source ~/.bashrc
3. host 检查一下 cuda 版本
nvcc -V
4. 运行 docker 容器
docker run -it -d \
-p 80:80 \
--gpus '"device=2,3"' \
--shm-size 32G \
--rm \
--name test\
pytorch/pytorch:2.0.1-cuda12.1-cudnn8-devel
总结
- Docker内包含CUDA,但不包含 Nvidia GPU Driver
- 宿主机的Nvidia GPU Driver驱动 必须大于 CUDA Toolkit要求的 Nvida GPU Driver驱动版本
- Docker的CUDA和主机的CUDA无关,但是Docker和宿主机的驱动有关,为了保证CUDA Toolkit的Nvidia GPU 驱动要求,宿主机 Nvidia GPU 驱动需要满足CUDA Toolkit的最低版本要求
回复 柚子 取消回复