一、 引子
你肯定遇到过这种情况:为了得到一个稳定、可预测的答案,你把大模型的“温度”(temperature)参数设为0,相当于关掉了它的“创意”开关。
然后满怀期待地输入同样的问题,结果……大模型还是给出了不一样的回答。这是什么玄学?这个困扰了许多开发者和用户的问题,背后其实是内核与数学的“小动作”。要讲清楚这事,咱们还得从温度系数说起。
二、 什么是温度系数,它有什么用?
简单来说,温度系数(temperature)是一个控制大模型输出随机性和创造性的参数。通过调整温度系数,可以让大模型的输出更加“严谨与固定”或者“充满想象和创造性”。
三、 温度系数如何作用于大模型?
大模型在每生成下一个词时,都会计算一个所有可能词汇的概率分布,然后根据概率分布来选择下一个词,温度系数的作用就是来“调整”这个概率分布的形状。
公式简化理解:调整后的概率 = Softmax(原始输出分数 / 温度)
- 当温度很高时(比如 1.5): 除以一个大于1的温度系数会缩小高分和低分之间的差距。概率最高的词优势不再那么明显,其他词的概率被相对抬高了。因此,模型的选择范围更广。效果: 概率分布变得“平坦”,采样的时候随机性更强,输出更有创造力和随机性。
- 当温度很低时(比如 0.2): 除以一个很小的温度系数会放大高分和低分之间的差距。概率最高的词会变得“更大概率”,而其他词的概率会被压得更低。因此,模型几乎总是选择那个最优解。效果: 概率分布变得“尖锐”,采样的时候更容易选择尖锐的点,也就是所谓的输出更加固定。
- 当温度设置为最低,也就是0时,模型不再从这个分布中进行随机抽样,而是直接、永远地选择概率最高的那个词。这个过程被称为“贪婪解码”。
四、 将温度系数设置为0,输入相同的情况下,为什么输出还是不固定?
遇事不决问大模型,各个大模型清一色的告诉我们,输出不固定是由以下两点共同导致:
- 浮点加法不满足结合律;
- GPU并行计算
第1点好理解,但第2点大模型的解释也是含糊其词。我们来一起仔细看看怎么回事。
1、 浮点加法不满足结合律
浮点数的加法很“娇气”,不满足结合律:
一个经典“量纲不齐”的例子:
因为浮点用“尾数 × 指数”的形式保存有限有效位。当你把数量级差很多的数相加时,小数会被“对齐”到大数的指数位,尾数精度不够就被截断/四舍五入,信息丢失;不同的加法顺序会在不同步骤发生舍入,因而得到不同结果。
还真是:数学不会骗人,但计算机会。
2、GPU并行归约:分组方式决定结果
显卡为了快,会把同一批计算切分成不同的“块”,再合并。不同批次(batch size)会触发不同的切分方式。切分方式不同 → 加法顺序不同 → 结果出现细微差异 → softmax 概率略微改变。如果 top-1 和 top-2 的分数本来就很接近,这点小差异就足以让最终 token 不一样。
听君一席话,如听一席话?
OK,下面咱们举个例子,
以单头注意力为例(忽略缩放与掩码):
softmax 公式如下:
在计算分母的时候,如果计算求和的顺序改变,根据浮点加法不满足结合律,就有可能使得分母的总和发生变化,从而导致最后的概率分布发生变化。
那么GPU在计算求和的时候,具体是怎么做的呢?
原来GPU内核中求和是通过“分块→块内求和→块间合并”的归约树实现的。
不同的 batch size 可能调用不同内核/分块切分策略(split-K 等),从而导致求和的顺序改变。
下图演示了相同的QueryA在不同batch size下的计算路径:
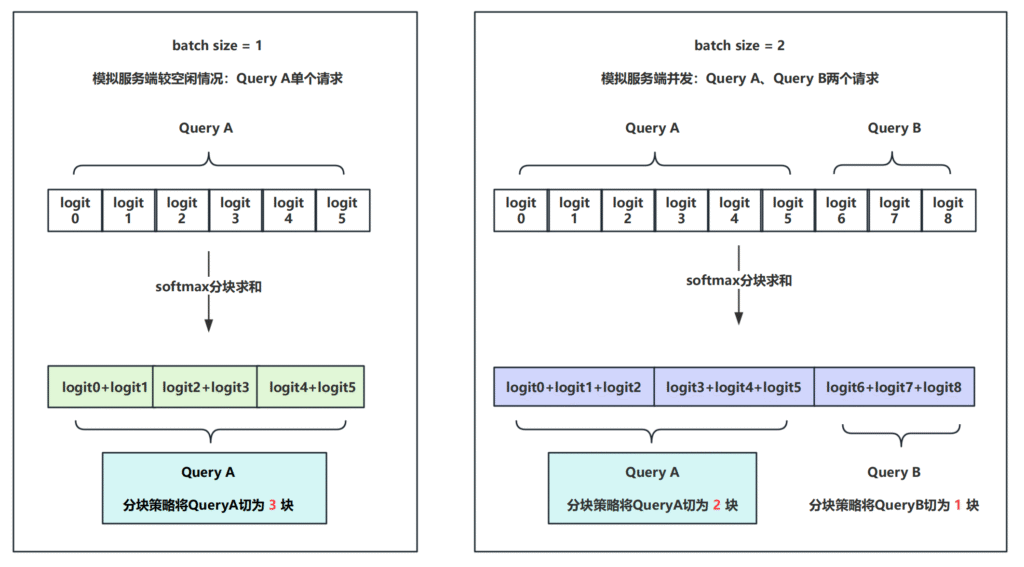
针对单个QueryA来说,
- 左边(3 块):分成三块(0–1, 2–3, 4–5),各自求和 → 最后再合。即:y1 = (logit0 + logit1) + (logit2 + logit3) + (logit4 + logit5)
- 右边(2 块):先把 6 个 logits 分成两块(0–2, 3–5),各自求和 → 最后再加。即:y2 = (logit0 + logit1 + logit2) + (logit3 + logit4 + logit5)
数学上这两种方式得到y1、y2的结果应当一样,但在浮点数下,y1并不等于y2:
- 不同分块大小导致加和顺序不同 = 不同舍入点
- → softmax 分母出现细微差异
- → softmax 概率分布略有不同
- → 如果 top-1 和 top-2 logits 差距很小,就可能使最终输出token发生变化。
所以:不确定性来自分块或者说归约树结构的变化。
五、如何确保输出固定?
固定 split-K 配置:不要随 batch/shape 动态选择,否则同一请求在不同批次下会触发不同归约树(求和路径)。
固定 block size 或 固定每块 token 数:在 attention 里,不让 prefill/decoding 动态决定 chunk 大小,而是固定一个分块粒度。
六、总结
- 大模型推理的不确定性,来源于:
- 浮点加法的不精确
- GPU分块归约的随意性
- 相同的query在温度值设置为0并且服务器端单并发的情况下,输出是固定的。一旦出现多并发,就可能出现输出不一样的情况。
- 推理端可以通过固定 split-K 配置、固定 block size的方式,让同一个query即使高并发的情况下,也保证输出的一致性。
发表回复